





PHPとOCR、Almalinuxで事務作業を効率化
通帳のOCRを実現した話の目次
過去の預金通帳の処理に困っていた
決算が近づき、未入金処理に追われていました。
しばらく放っておくと未入金額が1,000万円とかになるので、日々の入金確認が大事なのですが、これを人間の手で何とかしようと思うと、「記帳に行く>入金を確認する>顧客を特定>案件を特定>システムに登録>担当者に通知>未入金顧客には営業から連絡」というフローになるのですが、通帳を全て預けるのにも不安があるし、そのプロセスに1日1時間かければ、230時間以上が事務作業に費やされるわけです。時給1200円の事務さんだとすれば、最低でも記帳と入力に276,000円の経費、担当者への通達、経営者の把握、不明入金先の確認(一部名称では顧客を特定できない)を含めるともっと多くの時間的なコストがかかります。
ちなみにCSVでの取り込みはすでにスクレイピングで自動化してるのですが、通帳を読む必要がある場合の話です。
OCRは10年前から検討していた
OCR(Optical Character Recognition:光学的文字認識)という技術は昔からあったのですが、英語のフォントを中心とした技術であり、結局のところ日本語ではなかなか使えない技術でした。
人気税理士事務所でも結局は人の目で確認する必要があるので、機械的なOCRは利用していないとのことでした。
きっかけは手書き電子カルテのOCR自動入力
Tesseract 5.0を利用したOCRをPHPで作ってみたものの、やはり近年の学習データを使ってみてもその精度は高くありませんでした。
漢字よりもカタカナの識字が苦手のようで、「カ」「ワ」「ク」「ス」「フ」の区別がつかなかったりImagemagickで画像の濃淡を変えてみても識字率の向上は写真からでは難しかったです。スキャナを利用したスキャンデータではまだマシだったのですが、通帳のOCRのためにいちいちスキャナ通すような手間をかけるのは本末転倒で、手入力の方がマシです。
しかしながら歯科技工所から手書きのカルテを電子化して、データベースに保管したいという案件をいただき、google Vision APIを利用したことで、通帳のOCRに光が差し込みました。
問題は技術ではなくフロー設計
googleの開発したAPIは多くの学習済みデータを使うことで飛躍的に識字率を上げています。
JSONでデータを送ればテキストデータを返してくれる優れものです。
でもそこじゃないんですね。
通帳全部googleのAPIに送って、全部テキストデータで帰ってきても、それをどう切り出して代入するかがとても難しい。複数の入金データだけではなく、振替、引き落としなどのデータが混在したり、OCRが画像認識しても空白部分はテキスト化をそもそもしないためテキストの並びが崩れる問題、画像の明暗で文字を読み込めないなどなどの諸問題。
要はgoogleにこちらの都合の良いデータを返させるための努力の方が必要そうです。
とりあえず、SDKはインストール決定。
# vi /etc/yum.repos.d/google-cloud-sdk.repo
————————————
[google-cloud-sdk]
name=Google Cloud SDK
baseurl=https://packages.cloud.google.com/yum/repos/cloud-sdk-el8-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=0
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg
https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
—————————————
# dnf install google-cloud-sdk
# gcloud init
80%削減できれば良い
「OCR取り込み範囲を自動で認識、読み込みながら顧客情報と比較して、適切な案件の入金と見なす」
のようなことが出来たらいいのですが、通帳では無理です。
弊社との口座がある顧客は1400社くらいあるのですが、「特許業務法人」「司法書士法人」「その他行政機関の医療事業部」などは通帳記帳時点で、一文字かふた文字くらいしか特定できるワードが残らないし、行政機関は「●●シイリョウジギョウガントクブ」みたいな名前になると、はてどの学部から来た案件かそれとも実事業の案件か、という判断ができません。
なので、
- 通帳はスマホの写メで簡単に連続して撮りたい
- 通帳自体の印字がズレていることがあるので、読み込み範囲は手動
- チェックはどのみち必要なので顧客と案件との関連性は半自動で良い
- それ以外は自動
という目標を立てました。HEIC変換が必要そうなので、またサーバにツールをインストールします。
# dnf install git gcc-c++ automake libtool libjpeg-devel
# git clone https://github.com/strukturag/libde265.git
# cd libde265
# git checkout v1.0.8
# ./autogen.sh
# ./configure
# make install
# git clone https://github.com/strukturag/libheif.git
# ./autogen.sh
# PKG_CONFIG_PATH=/usr/local/lib/pkgconfig ./configure
# make install
そんでこのコマンドが使える
# heif-convert xxxxx.HEIC xxxxxxxxx.jpg
実際の設計は下記の通りです
- 管理画面からAjaxで連続アップロードを行いたいが、iPhone対応するため、heif-convertをインストールしてアップロード後自動でjpeg変換
- 通帳画像のモノクロかとコントラストの自動調整。余白率から明るさを-50〜-150までphpのImage関数を使い自動で調整する
- 銀行データベースを作り、記帳の枠組み比率はあらかじめ登録しておく。
- 手動で読み込みスタート位置をクリック一回で指定
- crontabで画像を起点から通帳の枠分切り出す。
- 画像をgoogle Vision APIにjsonで送信
- 戻り値は形成し、文字列の組み合わせ20パターンと比較、学習情報はデータベースに登録。次回以降は同じパターンについて自動的に顧客を紐づける。
- 案件との比較は手動で。同額の商品が多すぎるため
- 案件ごとに未入金かどうかを自動で比較
Vision APIがあるgoogle cloud platformは有料です。簡単に見積もるとOCRの1000読み込みで1.5ドル。上記のフロー中の読み込み数で計算したところ、大体通帳一冊読み込むコストは220円くらいでした。全然許容範囲です。銀行行って帰ってくるくらいの時間だけで、余裕でこのコストを超えます。
できた

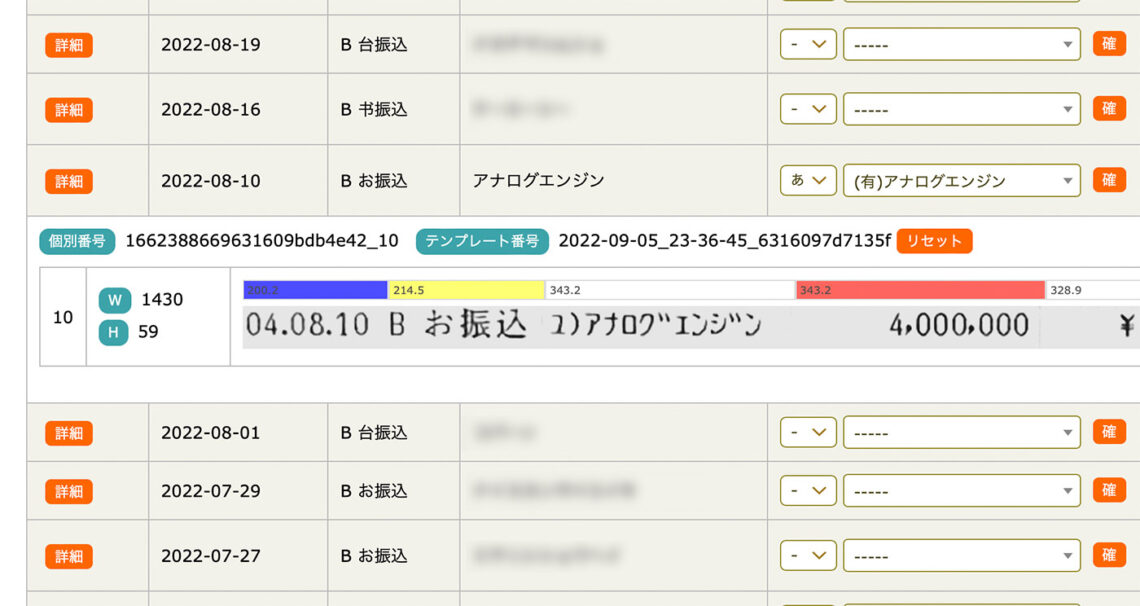
後は戻ってきたデータを顧客の予想名データベースと付き合わせて、確認ボタンを押せば、カルテへの反映と担当者・案件関係者に周知が自動でされます。
カスタマイズされたOCRを必要とするならぜひお問合せください。
現在は、上記のOCRのシステムを手書き対応し、医療用カルテ・指示書などのデジタル化なども行なっています。他にもさまざまな認識ができますので、システムでこんなことできないか、という思いがありましたら、ぜひ相談してください。
ものすごく適当に書いた文章読んでいただいてありがとうございました。

1999年、アナログエンジン創業。同社代表取締役。また滋賀新聞代表を兼務。一般社団法人中小企業個人情報セキュリティー推進協会DXアドバイザー検定スペシャリスト。全国広報コンクール2位のデザイナーでありながら、上場企業などのシステム設計を手掛ける。








